
Observability là gì? Tại sao Observability lại quan trọng ngày nay?

Hãy tưởng tượng triển khai một tính năng mới vào Prod — và có điều gì đó bị hỏng. Không có lỗi rõ ràng, không có cảnh báo, chỉ có một loạt claim từ người dùng. Nghe quen không 😀
Trong thế giới DevOps nhanh chóng ngày nay, nơi các hệ thống phức tạp, phân tán và liên tục phát triển, việc giám sát truyền thống không đủ. Nó cho bạn biết có điều gì đó sai, nhưng không cho biết tại sao lại sai.
Đây là lúc observability xuất hiện — không chỉ như một từ khóa, mà như một công cụ sinh tồn cho các đội ngũ kỹ thuật hiện đại.
Là các kỹ sư DevOps, chúng ta không chỉ cần cảnh báo — chúng ta cần câu trả lời.
What is Observability?
Khả năng quan sát là khả năng hiểu trạng thái bên trong của một hệ thống bằng cách kiểm tra các đầu ra của nó, bao gồm nhật ký, số liệu và dấu vết.
Sự khác biệt chính so với Monitoring:
- Monitoring cho bạn biết khi có điều gì đó sai.
- Observability giúp bạn hiểu tại sao nó sai.
Nói cách khác:
Monitoring giống như bảng điều khiển của một chiếc xe (tốc độ, cảnh báo nhiên liệu). Observability là có bộ công cụ chẩn đoán của thợ máy (nhật ký, dấu vết, chỉ số độ sâu…).
Tại sao Observability lại quan trọng trong các hệ thống hiện đại
Hiện tại, mỗi ứng dụng đều dựa trên Microservices và trải rộng ra nhiều hệ thống phân tán, vì vậy rất khó để gỡ lỗi một ứng dụng khi nó gặp sự cố.
Chỉ cần lấy một ví dụ: Một ứng dụng thương mại điện tử gặp sự cố khi thanh toán, vậy chúng ta có thể gợi ý ngay lập tức vị trí của sự cố thực tế hoặc nguyên nhân của sự cố không? KHÔNG!
Chúng ta cần kiểm tra service thanh toán, DB hoặc cấu hình mạng.
Tại đây, chúng tôi sử dụng observability để:
- Chẩn đoán sự cố và cải thiện hệ thống
- Hiểu hành vi của hệ thống
Các lý do khác có thể là:
Độ phức tạp của Cloud-Native: Dynamic scaling, container và các chức năng serverless làm tăng tính không thể đoán trước.
Trải nghiệm người dùng: Phát hiện vấn đề một cách chủ động trước khi người dùng phàn nàn.
Vai trò của Observability trong DevOps và SRE hiện đại
Giải quyết vấn đề chủ động: Observability cho phép các nhóm phát hiện các bất thường trước khi chúng ảnh hưởng đến người dùng, không chỉ phản ứng sau một sự cố.
Hỗ trợ CI/CD Pipelines: Continuous delivery cần sự tự tin. Observability đảm bảo rằng việc triển khai nhanh chóng không ảnh hưởng đến health của hệ thống.
Cải thiện MTTR (Mean Time To Resolve – Thời gian xử lý trung bình): Các bản theo dõi và nhật ký ngữ cảnh giảm thiểu sự đoán mò và cho phép phân tích nguyên nhân gốc nhanh hơn.
Enables Automation & Self-healing Systems: Với những hiểu biết theo thời gian thực, việc khắc phục tự động trở nên đáng tin cậy và có thể mở rộng.
Tăng Cường Sự Hợp Tác Giữa Dev và Ops: Tầm nhìn chia sẻ có nghĩa là cả hai đội có thể gỡ lỗi, sửa chữa và học hỏi cùng nhau bằng cách sử dụng cùng một dữ liệu.
Đảm bảo Sự Hài Lòng của Khách Hàng: Các nguyên tắc SRE dựa vào việc đạt được SLO. Observability là điều giúp duy trì chúng bằng cách giữ cho các dịch vụ reliable and available.
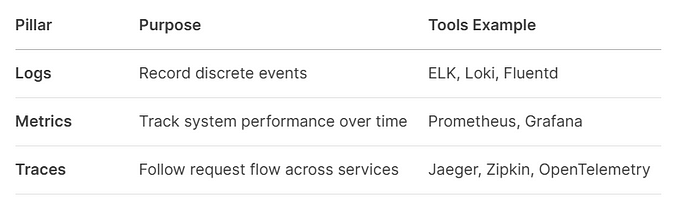
Nền tảng của Observability
Metric: Nó liên quan đến việc theo dõi các chỉ số hệ thống như CPU usage, memory usage, and network performance. Metric cung cấp cảnh báo dựa trên các ngưỡng và điều kiện đã được định nghĩa trước.
Monitoring tells us what is happening.
Logging (Logs): Nó liên quan đến việc thu thập dữ liệu log từ các thành phần khác nhau của một hệ thống.
Logging explains why it is happening.
Tracing (Traces): liên quan đến việc theo dõi luồng của một yêu cầu hoặc giao dịch khi nó di chuyển qua các dịch vụ và thành phần khác nhau trong một hệ thống.
Tracing shows how it is happening.
- Logs: “Chuyện gì xảy ra?” (e.g.,
ERROR: Payment failed at 3:00 PM). - Metrics: “Toang đến mức nào?” (e.g.,
API latency increased by 20000ms). - Traces: “Lỗi ở đâu biết không?” (e.g.,
Request stalled at Shipping Service).
Thách Thức trong Observability
- Data Overload: Too many logs/metrics → noise
- Tool Sprawl: Quản lý một lúc nhiều công cụ (e.g., Prometheus + ELK + Jaeger).
- Context Gaps: Liên kết đồng thời logs, metrics, and traces phải làm thủ công.
- Cost: Xây hệ thống, Lưu trữ và truy vấn dữ liệu observability có thể sẽ tốn kém.
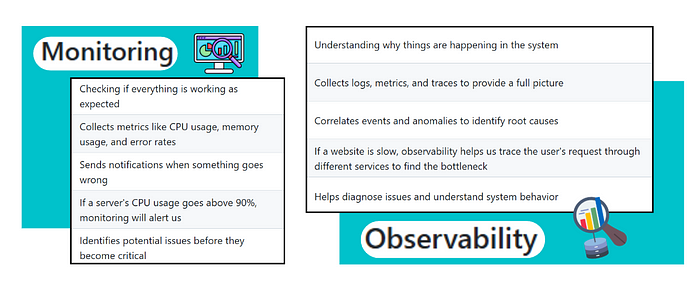
Observability vs. Monitoring
Đi vào thực tế nhé, vì tôi cũng chán với quá nhiều lý thuyết rồi.
Kịch bản: Một trang web chạy chậm.
Monitoring Approach:
- Cảnh báo nói rằng “High latency.”
Observability Approach:
- Logs: Hiển thị sự gia tăng lỗi Database.
- Metrics: CPU của ứng dụng đang high 95%.
- Metrics: Xác nhận một truy vấn chậm trong service
UserService.
Bài toán này tạm thời hold ở đây. Ngày thứ 2, chúng ta sẽ nói câu chuyện về metrics nhé!
Rảnh thì làm labs đi anh em nhé!